Explore how cryptographic verification is moving directly into capture devices. Every image captured by a modern camera passes through dozens of processing stages before it becomes a file. Color correction, noise reduction, compression—these transformations happen invisibly, in milliseconds, before the photograph ever reaches storage. This pipeline has been optimized for decades to produce better-looking images. Now it's being redesigned for something entirely different: trust. In-sensor cryptography represents a fundamental shift in how digital content establishes authenticity. Rather than adding verification layers after capture, these systems embed cryptographic signatures directly within the sensor hardware itself. The content is signed at the moment light hits silicon, before any downstream system can alter, manipulate, or fabricate the record. The move from AI policy to operational trust requires independent evidence. Synthetic Proof helps organizatio...
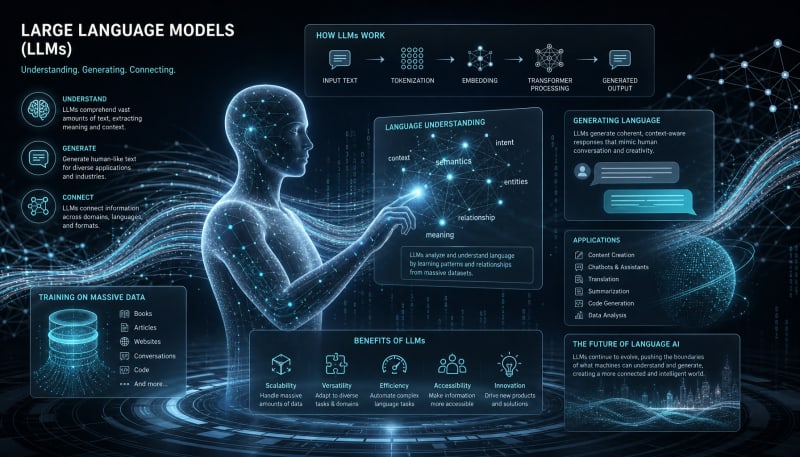
A practical explanation of the AI systems powering ChatGPT, Claude, Gemini, and modern assistants.
Large Language Models, or LLMs, have become the backbone of modern artificial intelligence applications. From chatbots and virtual assistants to content generation and code completion tools, these systems are reshaping how we interact with technology. But what exactly is an LLM, and how does it manage to understand and generate human-like text?
This article breaks down the fundamentals of large language models, exploring their architecture, training processes, and the mechanisms that enable them to process and produce language with remarkable proficiency.
Related: If you want the full operating system for AI workflows, prompts, ideation, and execution, Snapse OS brings the pieces together.
Defining Large Language Models
A large language model is a type of artificial intelligence system trained on massive amounts of text data to understand, interpret, and generate human language. The "large" in LLM refers to both the enormous datasets these models learn from and the billions of parameters that make up their neural network architecture.
Unlike traditional rule-based language systems that rely on explicit programming, LLMs learn patterns, grammar, context, and even reasoning abilities through exposure to vast quantities of text. This training enables them to predict what words or phrases should come next in a sequence, which forms the foundation of their language capabilities.
The Architecture Behind LLMs
Transformer Models
Most modern large language models are built on transformer architecture, introduced in 2017. Transformers use a mechanism called "attention" that allows the model to weigh the importance of different words in a sentence when processing language. This attention mechanism enables LLMs to understand context over long stretches of text, rather than just focusing on adjacent words.
The transformer architecture consists of multiple layers of neural networks, each containing attention mechanisms and feed-forward networks. These layers work together to create increasingly sophisticated representations of language, capturing everything from basic syntax to complex semantic relationships.
Parameters and Scale
Parameters are the adjustable weights within a neural network that the model learns during training. Large language models contain billions or even trillions of these parameters. GPT-3, for example, has 175 billion parameters, while some newer models exceed one trillion.
The number of parameters generally correlates with a model's capability to understand nuance and generate coherent, contextually appropriate responses. However, more parameters also mean greater computational requirements for both training and inference.
How LLMs Learn: The Training Process
Pre-training Phase
The training of large language models typically happens in two main stages. During pre-training, the model is exposed to enormous text datasets scraped from books, websites, articles, and other sources. This phase can involve hundreds of billions or even trillions of words.
The model learns by attempting to predict the next word in a sequence. When it makes a prediction, the system compares the output to the actual next word and adjusts the model's parameters to improve accuracy. This process repeats billions of times across the entire dataset, allowing the model to internalize patterns in language structure, common knowledge, and reasoning patterns.
Fine-tuning and Alignment
After pre-training, models undergo fine-tuning to specialize them for specific tasks or to align them with human preferences. This might involve training on curated datasets for particular applications, or using techniques like Reinforcement Learning from Human Feedback (RLHF) to make the model's outputs more helpful, harmless, and honest.
Fine-tuning allows a general-purpose language model to become more effective at specific tasks like question-answering, summarization, or following instructions while maintaining the broad knowledge acquired during pre-training.
How LLMs Generate Text
When you prompt an LLM with a question or instruction, the model doesn't "understand" language in the way humans do. Instead, it uses statistical patterns learned during training to generate the most probable sequence of words given the input.
The generation process works token by token (where tokens are pieces of words or individual words). The model examines your input, processes it through its layers of neural networks, and produces a probability distribution over all possible next tokens. It then selects a token based on this distribution—sometimes choosing the most likely option, sometimes sampling from the top candidates to introduce variation.
This process repeats, with each newly generated token being fed back into the model to predict the next one, until the model produces a complete response. The model considers the entire conversation history when generating each new token, which is why LLMs can maintain context across lengthy exchanges.
Key Capabilities of Large Language Models
Natural Language Understanding
LLMs can comprehend context, interpret ambiguous phrasing, and understand references and relationships between concepts mentioned across long passages of text. This allows them to answer questions, extract information, and engage in coherent dialogue.
Text Generation and Completion
Beyond understanding, LLMs excel at producing original text in various styles and formats. They can write articles, compose emails, create stories, generate code, and complete partial sentences or documents while maintaining consistency with the established context.
Translation and Transformation
Large language models can translate between languages, rewrite text in different tones or styles, summarize long documents, and transform information from one format to another—all without being explicitly programmed for each task.
Reasoning and Problem-Solving
Modern LLMs demonstrate emergent abilities to perform multi-step reasoning, solve mathematical problems, and break down complex questions into manageable components. While these capabilities have limitations, they represent a significant advancement in AI systems.
Limitations and Challenges
Despite their impressive capabilities, large language models have important limitations. They can generate plausible-sounding but factually incorrect information, a phenomenon known as "hallucination." They have knowledge cutoff dates and don't inherently know about events after their training period.
LLMs also lack true understanding or consciousness. They operate entirely on pattern recognition and statistical relationships, which means they can produce biased outputs reflecting biases in their training data. They struggle with tasks requiring precise calculation, consistent logical reasoning over many steps, or accessing real-time information.
Additionally, training and running large language models requires substantial computational resources, raising concerns about environmental impact and accessibility.
Conclusion
Large language models represent a significant breakthrough in artificial intelligence, leveraging transformer architecture and massive-scale training to process and generate human language with unprecedented capability. By learning statistical patterns from enormous text datasets and using attention mechanisms to understand context, LLMs can perform a wide range of language tasks from translation and summarization to question-answering and content creation.
Understanding what an LLM is and how it works provides essential context for evaluating these systems' capabilities and limitations. While they're powerful tools for language-related tasks, recognizing that they operate through pattern recognition rather than true understanding helps set appropriate expectations. As these models continue to evolve, their impact on communication, productivity, and human-computer interaction will only grow, making it increasingly important to grasp the fundamentals of how they function.
The Practical Solution
Consider LLMs as pattern-matching engines. When evaluating one for your work, test it on your actual use case with real examples—not demos or marketing claims. Pay attention to where it breaks, then decide if those failure modes are acceptable for your context.
— Kevin Marsh, Editor-in-Chief
SNAPSE OS
Build Your Full AI Workflow System
Get the full Snapse OS bundle with Prompt OS, ideation systems, and freelancer workflow tools in one operating system.
Explore Snapse OSSynthetic Proof
Verified — Editorial Layer
This content has passed editorial verification for clarity, accuracy, and trust alignment.
Editor-in-Chief: Kevin Marsh
Verification Status: PASSED
Verification Status: PASSED
Comments
Post a Comment